Consul: the end of CNAMEs and PuppetDB?
This blog explains how Consul can (and can not) replace PuppetDB, CNAME records and DNS servers in general.
March 20, 2015
I’d like you to meet vm123.shared.dc1.bc.int. Or, depending on who you ask, deploy.shared.dc1.bc.int, puppet.dc1.bc.int or F781139C-568B-459A-BADF-B971752291E6.
All these identifiers point to the very same collection of virtual hardware running the very same software. All these identifiers, however, are here for a reason. The UUID is used within the virtualization platform to identify the collection of virtual hardware; the vm123 hostname is used by the infrastructure team to identify the VM as an instance in the shared-services network in DC1. The deploy and puppet hostnames are used to identify the machine’s deployment and Puppet services.
Proven technology: DNS
Let’s forget the UUID for now, as it is only used within the virtualization platform, and focus on the hostnames. We use our trusty DNS server to manage these hostnames, and make sure they all point towards the same machine. This means we are setting up the following DNS records:
1.113.10.in-addr.arpa:
12 IN PTR vm123.shared.dc1.bc.int
shared.dc1.bc.int:
vm123 IN A 10.113.1.12
deploy IN CNAME vm123.shared.dc1.bc.int
dc1.bc.int:
puppet IN CNAME vm123.shared.dc1.bc.int
This actually works really well. Everyone can reach the machine using the hostname that’s most logical for them, and at the same time functionality can be seamlessly moved to a new or different machine if we choose to, and all the sysadmins need to do is update a CNAME record.
More proven technology: PuppetDB
Let me introduce you to an awesome application called Application A. It’s a stateless application running on a few servers and uses a Redis database. In front of it, I use HAProxy for load balancing. So it looks somewhat like this:
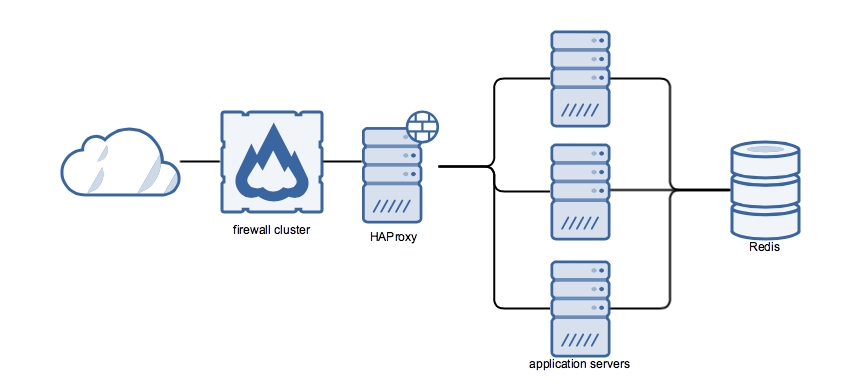
To wire it all together I just used CNAMES at first. HAProxy was pointing to 3 backend servers, called app[1-3].appa.dc1.bc.int, and the application servers were configured to use db.appa.dc1.bc.int as the DB backend. And all was fine.
However, when I wanted to add an extra application server, I actually needed to change quite a few pieces of configuration:
- Add new VM and configure it by applying the Puppet module
role::appa::appserver - Create the A and PTR records for the VM, as well as a CNAME record
app4.appa.dc1.bc.int - Add
app4as a backend in the HAProxy config - Add a firewall rule on
dbsoapp4can connect to Redis
And ofcourse all these changes needed to be ‘undone’ when I wanted to scale back. I could have just ignored the HAProxy config because it won’t use a backend that’s unreachable, but the stats UI would become a mess.
So I employed PuppetDB to dynamically add and remove backends in the HAProxy configuration and firewall rules on db. Awesome! I can now scale up and down, and my HAProxy and Redis boxes will get updated accordingly.
What’s wrong with this setup?
Just when you thought we were getting somewhere, I’m going to talk about reasons this setup is bad. But there actually are some things wrong (or at least ‘less than perfect’) with this setup:
- Changes are relatively slow: changes to DNS and Puppet are not instant. Adding new content to DNS is near-instant, but updates to existing records may take anywhere from a few minutes to many hours, depending on your TTL and zone-transfer settings (you are running more than one DNS server, right?). Changes to Puppet are not applied until the next Puppet run, and when dealing with exported resources, some changes may not show up until the second run, which usually means they are not showing up for another hour.
- Developers cannot easily make changes: Developers like speed. They hate waiting for (slow) ops people to update that DNS record, only a week after the devs asked for it. In most cases they can at most edit just parts of the Puppet code, and updating DNS themselves is usually out of the question.
- Redundancy: While most people are smart enough to run multiple DNS servers, it’s not uncommon to see just a single PuppetDB server. If PuppetDB is down, you have no data for your exported resources. Expect unexpected behavior.
- Puppet doesn’t scale very well: Using Puppet with exported resources requires the (standard) master/agent setup for Puppet. Unfortunately, this setup doesn’t scale all too well. Most smaller setups won’t run into this problem, but scaling across multiple datacenters certainly isn’t something you should try doing with a single Puppet setup.
Fixing the wrongs: Consul
So, we are used to having multiple names for the same server. We like using hostnames that indicate certain functionality, and that remain the same if we move functionality to another server. We like having some sort of central database of information that we can use to automatically configure certain aspects of our stack, like load-balancers and monitoring.
Now what we need is all of the above, in a scalable, realtime way. Preferably without requiring ops people to do all kinds of things (by hand) for developers.
What if I told you, you can have a highly scalable, multi-datacenter, highly fault tolerant, self-repairing piece of technology that can function as a key-value store, DNS server, and even health-checking tool? What if I told you it has a REST interface as well as a DNS interface, so devs as well as ops can register a service (like an app server or database) in it, thus claiming a completely logical hostname?
If that sounds pretty awesome to you, you should definitely check out Consul. In fact, check out the introduction to Consul right now if Consul is new to you.
Application A vs. Consul
Let’s get back to Application A. We set up our application platform using CNAME records and Puppet Exported Resources, but let’s change that to Consul. Here’s what would happen:
- CNAME records are deleted. Instead we adapt the Puppet module for each piece of functionality so it registers itself with Consul. This means the Redis server will tell Consul it has a service called
dbfor the application (or tag)appa. The service can be found on porttcp/6379and the IP address10.113.1.13. The application services would do something similar. - Consul would expose these services using logical DNS names that we can use in our config files. For instance, we can still configure our app servers to connect to
db.appa.dc1.bc.intand no matter what VM is actually running Redis, the app servers will connect to the correct Redis server. - HAProxy will get a list of backends from Consul by asking something like ‘can you give me a list of IP addresses and ports for all
appserverservices with theappatag?’. - Whenever a new app server is added or an existing one deleted, HAProxy will update its config.
- When an app server stops working, Consul will notice, mark the app server as ‘unhealthy’ and stop advertising it to HAProxy.
Automatic config updates? What’s that voodoo?
Unfortunately, no voodoo is involved in automatically updating the HAProxy config. Neither are unicorns, for that matter. These automatic updates are made possible by something called Consul Template. Consul Template is a standalone application that queries a Consul instance and updates any number of configuration files on your system; for instance the HAProxy config file.
Using Consul Template, changes that would require one or two Puppet runs on multiple machines (and therefore anywhere between a few minutes and one hour), are now near instant.
What about my old DNS?
At this point, it’s still a pretty good idea to keep managing your A and PTR records on your current DNS setup. In fact, if you are using something like Foreman you can automate this into your VM deployment process. You might still even throw in the odd CNAME. However, you add an extra zone configuration to your DNS server, pointing all queries for the Consul TLD (e.g. bc.consul) to the Consul cluster. This does require you to use a different TLD for the records inside Consul, but that would be a smart idea anyway. So, your DNS resolving will start looking somewhat like this:
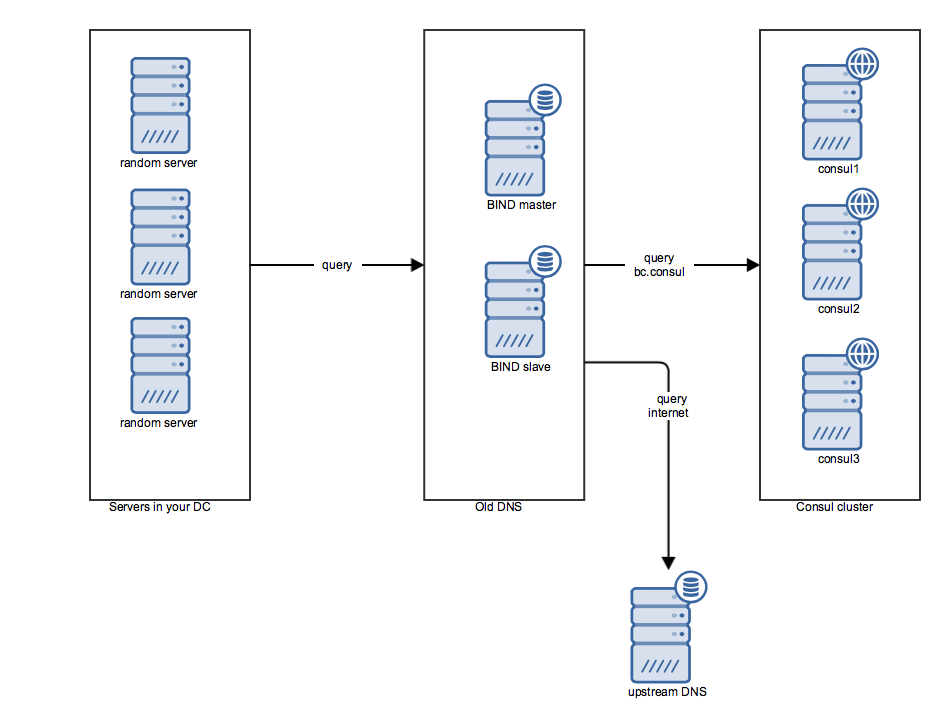
- Your servers send all their DNS queries to your DNS, whether they’re looking for
db.appa.dc1.bc.consul,vm123.shared.dc1.bc.intorhashicorp.com. - Your DNS setup will handle all queries it is authoritative for, for instance every domain under the
bc.intTLD. Queries forbc.consulwill be forwarded to Consul. All other queries are forwarded to an outside DNS (your hosting provider probably has a few). - Your Consul cluster will respond for all queries for
bc.consul.
As it stands now, your old DNS is not going anywhere yet.
And PuppetDB?
In theory, if you ‘Consul all the things’, you could probably do without PuppetDB, maybe even go to a master-less setup if you like. However, PuppetDB can happily co-exist with Consul while you upgrade all your Puppet modules to store their ‘exported data’ in Consul. Or you could use both.
What about Docker?
Everyone is talking about Docker. Yet I have only talked about ‘legacy’ infrastructure using VMs. The reason for this is that most companies are still using VMs in production, which makes them ever so relevant. So how does Docker fit in? Well, quite perfectly. In fact: Consul was developed with modern cloud- and container-based infrastructure in mind, and is very well suited for wiring containers together. It just happens to also fit in well with ‘legacy’ infrastructures. So if you are struggling with container-wiring or just looking for a good place to start your transition from legacy infrastructure to container-based infrastructure, deploying Consul might be the perfect first step.
Wrapping up
Consul can help you achieve most of the things you might currently use CNAME records and PuppetDB for. It’s far more scalable than PuppetDB, changes are near-instant, and thanks to good APIs it’s really easy to use for both devs and ops. If you are prepared to make some changes in your Puppet code it can easily replace PuppetDB. It can also replace most (or even all) of your CNAME records, and will happily co-exist with your current DNS, that you can (and will) still use for A and PTR records.
Consul may very well be (the beginning of) the end of PuppetDB and CNAMEs, but certainly not the end of your DNS setup. And if you’ve been looking into Docker, but still figuring out how you would wire all your containers together without getting lost, Consul might be the perfect place to start.